Difference between revisions of "Community/training"
(→Registration) |
(→Organization) |
||
| (94 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
| − | ''' | + | = '''Circle U, NLPL, & OpenEuroLLM 2026 Winter School on Multilinguality in LLM Development and Evaluation''' = |
| − | [[File: | + | [[File:Winter school 2025.jpg|center|thumb|upright=2.0]] |
= Background = | = Background = | ||
| − | + | In 2026, the NLPL network and Digital Europe | |
| − | project ''[https:// | + | project ''[https://openeurollm.eu OpenEuroLLM]'' |
have joined forces to organize the successful winter school series on Web-scale NLP. | have joined forces to organize the successful winter school series on Web-scale NLP. | ||
The winter school seeks to stimulate ''community formation'', | The winter school seeks to stimulate ''community formation'', | ||
| Line 13: | Line 13: | ||
and experience in using high-performance e-infrastructures for large-scale | and experience in using high-performance e-infrastructures for large-scale | ||
NLP research. | NLP research. | ||
| − | This | + | This 2026 edition of the winter school puts special emphasis on |
NLP researchers from countries who participate in the EuroHPC | NLP researchers from countries who participate in the EuroHPC | ||
| − | [https://www. | + | [https://www.eurohpc-ju.europa.eu/supercomputers/our-supercomputers_en consortium] |
| + | and is endorsed as a doctoral training event in the European | ||
| + | [https://www.circle-u.eu Circle U university alliance]. | ||
For additional background, please see the archival pages from the | For additional background, please see the archival pages from the | ||
[https://wiki.nlpl.eu/index.php/Community/training/2018 2018], | [https://wiki.nlpl.eu/index.php/Community/training/2018 2018], | ||
[https://wiki.nlpl.eu/index.php/Community/training/2019 2019], | [https://wiki.nlpl.eu/index.php/Community/training/2019 2019], | ||
[https://wiki.nlpl.eu/index.php/Community/training/2020 2020], | [https://wiki.nlpl.eu/index.php/Community/training/2020 2020], | ||
| − | [https://wiki.nlpl.eu/index.php/Community/training/2023 2023], | + | [https://wiki.nlpl.eu/index.php/Community/training/2023 2023], |
| − | [https://wiki.nlpl.eu/index.php/Community/training/2024 2024] | + | [https://wiki.nlpl.eu/index.php/Community/training/2024 2024], and |
| + | [https://wiki.nlpl.eu/index.php/Community/training/2025 2025] | ||
NLPL Winter Schools. | NLPL Winter Schools. | ||
| − | For early | + | For early 2026, NLPL will hold its winter school from Monday, February 2, to |
| − | Wednesday, February | + | Wednesday, February 4, 2026, at a |
[https://www.thonhotels.com/our-hotels/norway/skeikampen/ mountain-side hotel] | [https://www.thonhotels.com/our-hotels/norway/skeikampen/ mountain-side hotel] | ||
(with skiing and walking opportunities) about two hours north of Oslo. | (with skiing and walking opportunities) about two hours north of Oslo. | ||
| − | The project will organize group bus transfer from and to the Oslo | + | The project will organize group bus transfer from and to the main Oslo |
| − | airport ''Gardermoen'', leaving the airport at 9:45 on Monday morning | + | airport ''Gardermoen'' (OSL), leaving the airport at 9:45 on Monday morning |
and returning there around 17:30 on Wednesday afternoon. | and returning there around 17:30 on Wednesday afternoon. | ||
| − | The winter school is subsidized by the | + | The winter school is subsidized by the OpenEuroLLM project: there is no fee for |
participants and no charge for the bus transfer to and from the | participants and no charge for the bus transfer to and from the | ||
conference hotel. | conference hotel. | ||
All participants will have to cover their own travel and accommodation | All participants will have to cover their own travel and accommodation | ||
at Skeikampen, however. | at Skeikampen, however. | ||
| − | Two nights at the hotel, including all meals, will come to NOK | + | Two nights at the hotel, including all meals, will come to NOK 3885 (NOK 3485 per person in a shared double room), |
to be paid to the hotel directly upon arrival. | to be paid to the hotel directly upon arrival. | ||
= Programme = | = Programme = | ||
| − | The | + | The 2026 winter school has a thematic focus on ''Multilinguality in LLM Development and Evaluation''. |
| − | The programme | + | The programme is comprised of in-depth technical presentations (possibly including some |
| − | hands-on elements) by | + | hands-on elements) by international experts, with special emphasis on open science and European languages, but also includes critical reflections on current development trends in LLM-focused NLP. |
| − | but also | + | The programme will be complemented with a ‘walk-through’ of example EuroHPC experience |
| − | The programme will be complemented with a ‘walk-through’ of example experience | + | reports from the OpenEuroLLM consortium and with reflections about current LLM-oriented activities of the National Library of Norway. |
| − | reports | ||
Confirmed presenters and talks include: | Confirmed presenters and talks include: | ||
| − | * [https:// | + | * [https://bplank.github.io Barbara Plank], Ludwig Maximilian University of Munich |
| − | * [https:// | + | * [https://commoncrawl.org/team/laurie-burchell Laurie Burchell] and [https://commoncrawl.org/team/pedro-ortiz-suarez Pedro Ortiz Suarez], Common Crawl |
| − | * [https:// | + | * [https://www.linkedin.com/in/maximilianidahl/?originalSubdomain=de Max Idahl], ellamind |
| − | + | * [https://juliakreutzer.github.io Julia Kreutzer], Cohere for Labs | |
| − | * [https:// | + | * [https://geoalgo.github.io/ David Salinas], ELLIS Institute Tübingen |
| − | * [https:// | + | * [https://www.isir.upmc.fr/personnel/yvon/?lang=en François Yvon], Sorbonne Université |
| − | * [https:// | ||
= Schedule = | = Schedule = | ||
{| class="wikitable" | {| class="wikitable" | ||
|- | |- | ||
| − | !colspan=3|Monday, February | + | !colspan=3|Monday, February 2, 2026 |
|- | |- | ||
| 13:00 || 14:00 || Lunch | | 13:00 || 14:00 || Lunch | ||
|- | |- | ||
| − | | 14:00 || 15:30 || '''Session 1''' Pedro Ortiz Suarez | + | | 14:00 || 15:30 || '''Session 1''' [http://svn.nlpl.eu/outreach/skeikampen/2026/ortiz-burchell.pdf Laurie Burchell and Pedro Ortiz Suarez: Multilinguality at Common Crawl]<p class="mw-collapsible mw-collapsed">'''Improving Language Coverage for the Largest Open Web Corpus'''<br>The Common Crawl Foundation (CCF) provides the largest open corpus of web data, enabling a wide range of scientific and technical applications including large language model (LLM) development. However, our current data processing pipeline faces challenges when processing multilingual data, decreasing language representation and impacting downstream model performance. In this talk, we will discuss CCF’s initiatives to improve multilingual coverage and language identification of our web corpus. These efforts include soliciting crowd-sourced web seeds for under-served languages, running the First Workshop for Multilingual Data Quality Signals at COLM 2025, and creating CommonLID, a community-driven, human-annotated language identification benchmark for the web domain. Throughout, we emphasise the collaborative nature of our efforts, working in partnership with members of the NLP community to improve content available in their languages.</p> |
|- | |- | ||
| 15:30 || 15:50 || Coffee Break | | 15:30 || 15:50 || Coffee Break | ||
|- | |- | ||
| − | | 16:00 || 17:30 || '''Session 2''' | + | | 16:00 || 17:30 || '''Session 2''' [http://svn.nlpl.eu/outreach/skeikampen/2026/yvon1.pdf François Yvon: Evaluating Large LMs and their Multilingualism]<p class="mw-collapsible mw-collapsed">Large Language Models introduced in the recent years have been found extremely helpful to advance the state-of-the-art in many Natural Language Applications, notably due to their ability to compute numerical, high-dimensional, representations of linguistic units such as words or sentences. Multilingual language models go one step further and add the ability to handle multiple languages, sometimes even multiple scripts, with just one single model. In this presentation, I will discuss multilingual language models at length, with a focus on the evaluation of their multilingual abilities, which raises two difficult questions: (a) to evaluate their performance as if they were just a collection of monolingual models; (b) to evaluate their performance as integrated multilingual models, capable of bridging between languages. </p> |
|- | |- | ||
| 17:30 || 17:50 || Coffee Break | | 17:30 || 17:50 || Coffee Break | ||
|- | |- | ||
| − | | 17:50 || 19:20 || '''Session 3''' | + | | 17:50 || 19:20 || '''Session 3''' [http://svn.nlpl.eu/outreach/skeikampen/2026/kreutzer1.pdf Julia Kreutzer: Evaluating Generations Multilingually] <p class="mw-collapsible mw-collapsed">'''Current Challenges and Lessons from Machine Translation'''<br>In this session we will dive into the particular challenge of evaluating LLMs across many languages in generative tasks. We will take a look at the "sister field" of machine translation and inspect what principles have led to advances in understanding quality across languages. </p> |
|- | |- | ||
| 19:30 || || Dinner | | 19:30 || || Dinner | ||
| Line 81: | Line 82: | ||
{| class="wikitable" | {| class="wikitable" | ||
|- | |- | ||
| − | !colspan=3|Tuesday, February | + | !colspan=3|Tuesday, February 3, 2026 |
|- | |- | ||
|colspan=3 | Breakfast is available from 07:30 | |colspan=3 | Breakfast is available from 07:30 | ||
|- | |- | ||
| − | | 09:00 || 10:30 || '''Session 4''' | + | | 09:00 || 10:30 || '''Session 4''' [http://svn.nlpl.eu/outreach/skeikampen/2026/yvon2.pdf François Yvon: Text Generation: Know your Options!] <p class="mw-collapsible mw-collapsed">Text generation, contextual or non-contextual, is ubiquitous in the current LLM era, as it serves as the most basic block in multiple application contexts, from question answering and dialog systems to text summarization and machine translation, and many more. Generation is thus equally useful to compute deterministic and highly non-deterministic mappings with various level of output constraints. Furthermore, text generation is also used as a sub-routine of more complex generation strategies, aiming to produce syntactically well-formed (e.g. for code generation) or semantically consistent outputs, possibility through multiple steps of generation (e.g, in chain-of-thoughts generation) or to collect diverse samples from the generating distribution. To cover this considerable diversity of uses, multiple text generation strategies have been proposed, some less well-known than others. In this talk I will review various families of generation algorithms, from the most basic ones to the more sophisticated approaches, so as to document, as much as possible, the possible options that are available to text generation users. The final part will survey some decoding issues that are specific to multilingual models. </p> |
|- | |- | ||
|colspan=3| Free time (Lunch is available between 13:00 and 14:30) | |colspan=3| Free time (Lunch is available between 13:00 and 14:30) | ||
|- | |- | ||
| − | | 15:30 || 17:00 || '''Session 5''' | + | | 15:30 || 17:00 || '''Session 5''' [http://svn.nlpl.eu/outreach/skeikampen/2026/idahl.pdf Max Idahl: Multilingual Model-Based Quality Filtering for LLM Pretraining]<p class="mw-collapsible mw-collapsed">Data quality is the highest-leverage factor for LLM performance, with recent work showing significant training efficiency gains through careful curation. This presentation traces the evolution from rule-based filtering to modern model-based approaches that now work across dozens of languages. We cover the progression from basic perplexity-based filters, to FastText and encoder-based scorers, to our newly released Propella models that annotate documents across 18 properties for 57 languages at scale. The talk includes practical insights into building multilingual filtering pipelines.</p> |
|- | |- | ||
| 17:00 || 17:20 || Coffee Break | | 17:00 || 17:20 || Coffee Break | ||
|- | |- | ||
| − | | 17:20 || | + | | 17:20 || 19:20 || '''Session 6''' [http://svn.nlpl.eu/outreach/skeikampen/2026/salinas.pdf David Salinas: Challenges in Evaluating Generative Models]<p class="mw-collapsible mw-collapsed">In this talk, we will discuss the evaluation of generative models, in particular Large Language Models (LLMs). Given that such models produce open-ended output, their evaluation requires different techniques than static evaluations such as simple question-answering benchmarks. We will first discuss human annotations and their use in leaderboards such as LMArena and ComparIA. We will then focus on automatic evaluation relying on LLM judges. In particular, we will describe current challenges with LLM judges before discussing their application in multilingual settings.</p> |
|- | |- | ||
| 19:30 || || Dinner | | 19:30 || || Dinner | ||
|- | |- | ||
| − | | 21:00 || || '''Evening Session''' | + | | 21:00 || || '''Evening Session''':<br/> |
| + | [http://svn.nlpl.eu/outreach/skeikampen/2026/nb.pdf Javier de la Rosa, Rolv-Arild Braaten, Marthe Midtgaard, Angelina Zanardi: National Library of Norway]<br/> | ||
| + | [http://svn.nlpl.eu/outreach/skeikampen/2026/openeurollm.pdf Sampo Pyysalo, Max Idahl, David Salias, Stephan Oepen, Shenbin Qian: OpenEuroLLM, MultiSynt] | ||
|} | |} | ||
| Line 103: | Line 106: | ||
{| class="wikitable" | {| class="wikitable" | ||
|- | |- | ||
| − | !colspan=3|Wednesday, February | + | !colspan=3|Wednesday, February 4, 2026 |
|- | |- | ||
|colspan=3| Breakfast is available from 07:30 | |colspan=3| Breakfast is available from 07:30 | ||
|- | |- | ||
| − | | 08:30 || 10:00 || '''Session 8''' | + | | 08:30 || 10:00 || '''Session 8''' [http://svn.nlpl.eu/outreach/skeikampen/2026/plank.pdf Barbara Plank: NLP Beyond the Standard]<p class="mw-collapsible mw-collapsed">'''Dialects, Variation, and Shared Representations in Multilingual Language Models'''<br>Multilingual language models have primarily focused on cross-lingual differences, with intra-language variation only recently gaining more attention. Dialects and non-standard varieties challenge core assumptions about data, representation, and evaluation. In this talk, I discuss what makes dialects particularly challenging for multilingual models, review approaches starting from early encoder-based methods, and give an overview of resources developed for dialectal NLP, with a focus on German dialects. I then turn to recent work on multilingual training dynamics and shared representations, analyzing when linguistic information and shared concept spaces emerge during training and where alignment breaks down. Although dialects are not yet explicitly modeled in this analysis, the findings provide insight into multilingual representation learning during pre-training. </p> |
|- | |- | ||
| 10:00 || 10:30 || Coffee Break | | 10:00 || 10:30 || Coffee Break | ||
|- | |- | ||
| − | | 10:30 || 12:00 || '''Session 9''' | + | | 10:30 || 12:00 || '''Session 9''' [http://svn.nlpl.eu/outreach/skeikampen/2026/kreutzer2.pdf Julia Kreutzer: Optimizing Data for Multilingual Post-Training] <p class="mw-collapsible mw-collapsed">In this session we will look into techniques for augmenting data collections for better multilingual coverage. We will discuss the role of translation and inference settings, and explore methods for optimizing multilingual data both on the prompt and the generation side.</p> |
|- | |- | ||
| 12:30 || 13:30 || Lunch | | 12:30 || 13:30 || Lunch | ||
| Line 120: | Line 123: | ||
= Registration = | = Registration = | ||
| − | In total, | + | In total, we expect 60–70 participants at the 2026 winter school. |
| − | + | Registration for interested participants is now closed. | |
| − | + | Requests for participation were processed on a first-come, first-served basis, with an eye toward regional balance. | |
| − | Interested parties who | + | Interested parties who have submitted the registration form were confirmed in three batches, on '''November 28''', on '''December 5''', |
| − | and on '''December | + | and on '''December 19''', which was also the closing date for winter school registration. |
Once confirmed by the organizing team, participant names are published | Once confirmed by the organizing team, participant names are published | ||
| Line 136: | Line 139: | ||
With a few exceptions, winter school participants travel to and from the conference hotel | With a few exceptions, winter school participants travel to and from the conference hotel | ||
| − | jointly on a chartered bus (the | + | jointly on a chartered bus (the OpenEuroLLM shuttle). |
| − | The bus will leave OSL airport no later than 9:45 CET on Monday, February | + | The bus will leave OSL airport no later than 9:45 CET on Monday, February 2. |
Thus, please meet up by 9:30 and make your arrival known to your assigned | Thus, please meet up by 9:30 and make your arrival known to your assigned | ||
‘tour guide’ (who will introduce themselves to you by email beforehand). | ‘tour guide’ (who will introduce themselves to you by email beforehand). | ||
| Line 145: | Line 148: | ||
to the left as one exits the customs area: | to the left as one exits the customs area: | ||
the yellow dot numbered (18) on the | the yellow dot numbered (18) on the | ||
| − | [https://avinor.no/ | + | [https://www.avinor.no/siteassets/flyplasser/oslo-lufthavn/info/kart-over-flyplassen/kart-over-flyplassen-ankomst-oslo-lufthavn-avinor.jpg OSL arrivals map]. |
The group will then walk over to the bus terminal, to leave the airport not long after 9:40. | The group will then walk over to the bus terminal, to leave the airport not long after 9:40. | ||
| − | The drive to the Skeikampen conference hotel will take us about three hours, and the bus | + | The drive to the Skeikampen conference hotel will take us about two-three hours, and the bus |
will make one stop along the way to stretch our legs and fill up on coffee. | will make one stop along the way to stretch our legs and fill up on coffee. | ||
| − | The winter school will end with lunch on Wednesday, February | + | The winter school will end with lunch on Wednesday, February 4, before the group returns |
| − | to OSL airport on the | + | to OSL airport on the OpenEuroLLM shuttle. |
The bus will leave Skeikampen at 14:00 CET, with an expected arrival time at OSL | The bus will leave Skeikampen at 14:00 CET, with an expected arrival time at OSL | ||
around 17:00 to 17:30 CET. After stopping at the OSL airport, the bus will continue to central Oslo. | around 17:00 to 17:30 CET. After stopping at the OSL airport, the bus will continue to central Oslo. | ||
| Line 157: | Line 160: | ||
= Organization = | = Organization = | ||
| − | The | + | The 2026 Winter School is organized by a team of volunteers at the University |
| − | of Oslo, supported by a programme committee from the | + | of Oslo, supported by a programme committee from the OpenEuroLLM, Circle U, and |
| − | please see below. | + | NLPL networks and beyond, please see below. |
For all inquiries regarding registration, the programme, logistics, | For all inquiries regarding registration, the programme, logistics, | ||
| − | or such, please contact <code> | + | or such, please contact <code>nlpl-training@ifi.uio.no</code>. |
| − | The programme committee is comprised of: | + | The programme committee is comprised of (in alphabetical order): |
| − | * | + | * Jenia Jitsev (Forschungszentrum Jülich, Germany) |
| − | * Andrey Kutuzov (University of Oslo, Norway) | + | * '''Andrey Kutuzov''' (University of Oslo, Norway) |
| − | * Stephan Oepen (University of Oslo, Norway) | + | * Alessandro Lenci (University of Pisa, Italy) |
| + | * '''Stephan Oepen''' (University of Oslo, Norway) | ||
* Sampo Pyysalo (University of Turku, Finland) | * Sampo Pyysalo (University of Turku, Finland) | ||
| + | * David Salinas (ELLIS Institute, Germany) | ||
| + | * Gema Ramirez-Sanches (Prompsit Language Engineering, Spain) | ||
* Jörg Tiedemann (University of Helsinki, Finland) | * Jörg Tiedemann (University of Helsinki, Finland) | ||
| + | * Joaquin Vanschoren (Eindhoven University of Technology, The Netherlands) | ||
| + | * Guillaume Wisniewski (Paris Cité University, France) | ||
= Participants = | = Participants = | ||
| − | + | # Adam Hrin, AMD Silo AI (Finland) | |
| − | # | + | # Agnes Toftgård, The National Library (Sweden) |
| − | # | + | # Alicia Núñez Alcover, Prompsit (Spain) |
| − | # | + | # Anastasia Philipps, University of Oslo (Norway) |
| − | # | + | # Andrey Kutuzov, University of Oslo (Norway) |
| − | # | + | # Angelina Zanardi, National Library of Norway |
| − | # | + | # Anni Moisala, CSC – IT Center for Science (Finland) |
| − | # | + | # Artūrs Znotiņš, University of Latvia (Latvia) |
| + | # Barbara Heinisch, Eurac Research (Italy) | ||
| + | # Barbara Plank, Ludwig-Maximilians-Universität München (Germany) | ||
| + | # Charlotte Noel, LINAGORA Labs (France) | ||
| + | # Dalton Harmsen, Eindhoven University of Technology (Netherlands) | ||
| + | # David Salinas, ELLIS institute Tübingen (Germany) | ||
| + | # Diana Kylymnyk, University of Exeter (UK) | ||
| + | # Elizaveta Kuzmenko, Université Libre de Bruxelles (Belgium) | ||
| + | # Etienne Simon, University of Oslo (Norway) | ||
| + | # Faton Rekathati, The National Library (Sweden) | ||
| + | # Fedor Vitiugin, University of Turku (Finland) | ||
| + | # François Yvon, CNRS (France) | ||
| + | # Fred Philippy, University of Luxembourg (Luxembourg) | ||
| + | # Ghulam Muhammed Khan, University of Exeter (United Kingdom) | ||
| + | # Gianluca Barmina, University of Southern Denmark (Denmark) | ||
# Hannah Clausen, University of Oslo (Norway) | # Hannah Clausen, University of Oslo (Norway) | ||
| − | # | + | # Hannan Mahadik, ELLIS Institute Tübingen (Germany) |
| − | # | + | # Iglika Nikolova-Stoupak, Sorbonne Université (France) |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
# Jan Hajič, Charles University (Czech Republic) | # Jan Hajič, Charles University (Czech Republic) | ||
| − | # Jindřich Helcl, Charles University (Czech Republic) | + | # Jiajing Wan, University of Bergen (Norway) |
| − | # | + | # Jindřich Helcl, University of Oslo (Norway) |
| − | # | + | # Johannes Gabriel Sindlinger, IT University of Copenhagen (Denmark) |
| − | # | + | # Jouni Luoma, AMD Silo AI (Finland) |
| − | # | + | # Julia Kreutzer, Cohere Labs (Canada) |
| − | # | + | # Justyna Sikora, The National Library (Sweden) |
| − | # | + | # Katarina Strani Herriot-Watt University (United Kingdom) |
| − | # | + | # Kevin Glocker, Linköping University (Sweden) |
| − | # | + | # Kristýna Onderková, Charles University (Czech Republic) |
| − | # | + | # Laurène Cave, Sorbonne Université (France) |
| − | # | + | # Lisa Yankovskaya, University of Tartu (Estonia) |
| − | # | + | # Maja Buljan, University of Oslo (Norway) |
| − | # | + | # Markus Heiervang, National Library of Norway |
| − | # | + | # Marthe Midtgaard, National Library of Norway |
| + | # Mattes Ruckdeschel, IT University of Copenhagen (Denmark) | ||
| + | # Maximilian Idahl, ellamind (Germany) | ||
| + | # Meihan Tong, University of Oslo (Norway) | ||
| + | # Muhammad Imran, University of A Coruña (Spain) | ||
| + | # Nam Luu, Charles University (Czech Republic) | ||
| + | # Neda Jamshidi, University of Sienna (Italy) | ||
| + | # Nikolay Arefev, University of Oslo (Norway) | ||
| + | # Nils Grünefeld, IT University of Copenhagen (Denmark) | ||
| + | # Pedro Ortiz Suarez, Common Crawl Foundation (USA) | ||
| + | # Rolv-Arild Braaten, National Library of Norway | ||
| + | # Romina Oji, Linköping University (Sweden) | ||
| + | # Sampo Pyysalo, University of Turku (Finland) | ||
| + | # Shanshan Xu, University of Copenhagen (Denmark) | ||
| + | # Shenbin Qian, University of Oslo (Norway) | ||
| + | # Stephan Oepen, University of Oslo (Norway) | ||
| + | # Taja Kuzman Pungeršek, Jožef Stefan Institute (Slovenia) | ||
| + | # Tita Enstad, National Library of Norway | ||
| + | # Tommaso Green, University of Mannheim (Germany) | ||
| + | # Tudor Nicolae Mateiu, Prompsit (Spain) | ||
# Vladislav Mikhailov, University of Oslo (Norway) | # Vladislav Mikhailov, University of Oslo (Norway) | ||
| − | # | + | # Wafa Aissa, UCLouvain (Belgium) |
| − | + | # Xiaorui Yu, King's College London (UK) | |
| − | + | # Yihang Lu, Sorbonne Université (France) | |
| − | # | + | # Yiheng Wu, University of Helsinki (Finland) |
| − | + | # Yves Scherrer, University of Oslo (Norway) | |
| − | + | # Zihao Li, University of Helsinki (Finland) | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | # | ||
| − | # | ||
| − | |||
| − | |||
| − | # | ||
| − | # | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
Latest revision as of 13:53, 31 May 2026
Contents
Circle U, NLPL, & OpenEuroLLM 2026 Winter School on Multilinguality in LLM Development and Evaluation

Background
In 2026, the NLPL network and Digital Europe project OpenEuroLLM have joined forces to organize the successful winter school series on Web-scale NLP. The winter school seeks to stimulate community formation, i.e. strengthening interaction and collaboration among European research teams in NLP and advancing a shared level of knowledge and experience in using high-performance e-infrastructures for large-scale NLP research. This 2026 edition of the winter school puts special emphasis on NLP researchers from countries who participate in the EuroHPC consortium and is endorsed as a doctoral training event in the European Circle U university alliance. For additional background, please see the archival pages from the 2018, 2019, 2020, 2023, 2024, and 2025 NLPL Winter Schools.
For early 2026, NLPL will hold its winter school from Monday, February 2, to Wednesday, February 4, 2026, at a mountain-side hotel (with skiing and walking opportunities) about two hours north of Oslo. The project will organize group bus transfer from and to the main Oslo airport Gardermoen (OSL), leaving the airport at 9:45 on Monday morning and returning there around 17:30 on Wednesday afternoon.
The winter school is subsidized by the OpenEuroLLM project: there is no fee for participants and no charge for the bus transfer to and from the conference hotel. All participants will have to cover their own travel and accommodation at Skeikampen, however. Two nights at the hotel, including all meals, will come to NOK 3885 (NOK 3485 per person in a shared double room), to be paid to the hotel directly upon arrival.
Programme
The 2026 winter school has a thematic focus on Multilinguality in LLM Development and Evaluation. The programme is comprised of in-depth technical presentations (possibly including some hands-on elements) by international experts, with special emphasis on open science and European languages, but also includes critical reflections on current development trends in LLM-focused NLP. The programme will be complemented with a ‘walk-through’ of example EuroHPC experience reports from the OpenEuroLLM consortium and with reflections about current LLM-oriented activities of the National Library of Norway.
Confirmed presenters and talks include:
- Barbara Plank, Ludwig Maximilian University of Munich
- Laurie Burchell and Pedro Ortiz Suarez, Common Crawl
- Max Idahl, ellamind
- Julia Kreutzer, Cohere for Labs
- David Salinas, ELLIS Institute Tübingen
- François Yvon, Sorbonne Université
Schedule
| Monday, February 2, 2026 | ||
|---|---|---|
| 13:00 | 14:00 | Lunch |
| 14:00 | 15:30 | Session 1 Laurie Burchell and Pedro Ortiz Suarez: Multilinguality at Common Crawl Improving Language Coverage for the Largest Open Web Corpus |
| 15:30 | 15:50 | Coffee Break |
| 16:00 | 17:30 | Session 2 François Yvon: Evaluating Large LMs and their Multilingualism Large Language Models introduced in the recent years have been found extremely helpful to advance the state-of-the-art in many Natural Language Applications, notably due to their ability to compute numerical, high-dimensional, representations of linguistic units such as words or sentences. Multilingual language models go one step further and add the ability to handle multiple languages, sometimes even multiple scripts, with just one single model. In this presentation, I will discuss multilingual language models at length, with a focus on the evaluation of their multilingual abilities, which raises two difficult questions: (a) to evaluate their performance as if they were just a collection of monolingual models; (b) to evaluate their performance as integrated multilingual models, capable of bridging between languages. |
| 17:30 | 17:50 | Coffee Break |
| 17:50 | 19:20 | Session 3 Julia Kreutzer: Evaluating Generations Multilingually Current Challenges and Lessons from Machine Translation |
| 19:30 | Dinner | |
| Tuesday, February 3, 2026 | ||
|---|---|---|
| Breakfast is available from 07:30 | ||
| 09:00 | 10:30 | Session 4 François Yvon: Text Generation: Know your Options! Text generation, contextual or non-contextual, is ubiquitous in the current LLM era, as it serves as the most basic block in multiple application contexts, from question answering and dialog systems to text summarization and machine translation, and many more. Generation is thus equally useful to compute deterministic and highly non-deterministic mappings with various level of output constraints. Furthermore, text generation is also used as a sub-routine of more complex generation strategies, aiming to produce syntactically well-formed (e.g. for code generation) or semantically consistent outputs, possibility through multiple steps of generation (e.g, in chain-of-thoughts generation) or to collect diverse samples from the generating distribution. To cover this considerable diversity of uses, multiple text generation strategies have been proposed, some less well-known than others. In this talk I will review various families of generation algorithms, from the most basic ones to the more sophisticated approaches, so as to document, as much as possible, the possible options that are available to text generation users. The final part will survey some decoding issues that are specific to multilingual models. |
| Free time (Lunch is available between 13:00 and 14:30) | ||
| 15:30 | 17:00 | Session 5 Max Idahl: Multilingual Model-Based Quality Filtering for LLM Pretraining Data quality is the highest-leverage factor for LLM performance, with recent work showing significant training efficiency gains through careful curation. This presentation traces the evolution from rule-based filtering to modern model-based approaches that now work across dozens of languages. We cover the progression from basic perplexity-based filters, to FastText and encoder-based scorers, to our newly released Propella models that annotate documents across 18 properties for 57 languages at scale. The talk includes practical insights into building multilingual filtering pipelines. |
| 17:00 | 17:20 | Coffee Break |
| 17:20 | 19:20 | Session 6 David Salinas: Challenges in Evaluating Generative Models In this talk, we will discuss the evaluation of generative models, in particular Large Language Models (LLMs). Given that such models produce open-ended output, their evaluation requires different techniques than static evaluations such as simple question-answering benchmarks. We will first discuss human annotations and their use in leaderboards such as LMArena and ComparIA. We will then focus on automatic evaluation relying on LLM judges. In particular, we will describe current challenges with LLM judges before discussing their application in multilingual settings. |
| 19:30 | Dinner | |
| 21:00 | Evening Session: Javier de la Rosa, Rolv-Arild Braaten, Marthe Midtgaard, Angelina Zanardi: National Library of Norway | |
| Wednesday, February 4, 2026 | ||
|---|---|---|
| Breakfast is available from 07:30 | ||
| 08:30 | 10:00 | Session 8 Barbara Plank: NLP Beyond the Standard Dialects, Variation, and Shared Representations in Multilingual Language Models |
| 10:00 | 10:30 | Coffee Break |
| 10:30 | 12:00 | Session 9 Julia Kreutzer: Optimizing Data for Multilingual Post-Training In this session we will look into techniques for augmenting data collections for better multilingual coverage. We will discuss the role of translation and inference settings, and explore methods for optimizing multilingual data both on the prompt and the generation side. |
| 12:30 | 13:30 | Lunch |
| 13:45 | 16:45 | Bus transfer to OSL Airport |
Registration
In total, we expect 60–70 participants at the 2026 winter school. Registration for interested participants is now closed. Requests for participation were processed on a first-come, first-served basis, with an eye toward regional balance. Interested parties who have submitted the registration form were confirmed in three batches, on November 28, on December 5, and on December 19, which was also the closing date for winter school registration.
Once confirmed by the organizing team, participant names are published on this page, and registration establishes a binding agreement with the hotel. Therefore, a cancellation fee will be incurred (unless we can find someone else to ‘take over’ last-minute spaces), and no-shows will be charged the full price for at least one night by the hotel.
Logistics
With a few exceptions, winter school participants travel to and from the conference hotel jointly on a chartered bus (the OpenEuroLLM shuttle). The bus will leave OSL airport no later than 9:45 CET on Monday, February 2. Thus, please meet up by 9:30 and make your arrival known to your assigned ‘tour guide’ (who will introduce themselves to you by email beforehand).
The group will gather near the DNB currency exchange booth in the downstairs arrivals area, just outside the international arrivals luggage claims and slightly to the left as one exits the customs area: the yellow dot numbered (18) on the OSL arrivals map. The group will then walk over to the bus terminal, to leave the airport not long after 9:40. The drive to the Skeikampen conference hotel will take us about two-three hours, and the bus will make one stop along the way to stretch our legs and fill up on coffee.
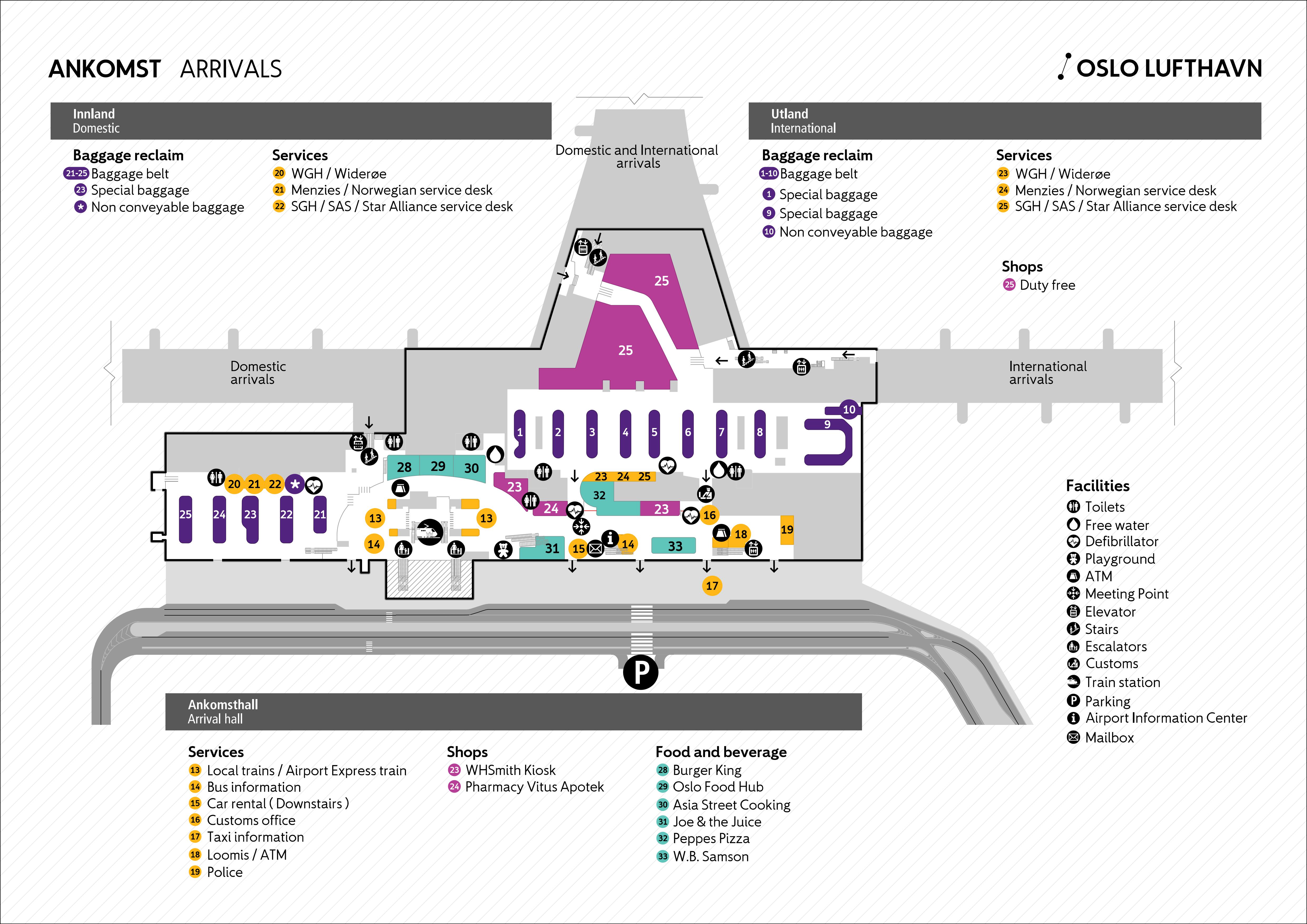{kind=link}
The winter school will end with lunch on Wednesday, February 4, before the group returns to OSL airport on the OpenEuroLLM shuttle. The bus will leave Skeikampen at 14:00 CET, with an expected arrival time at OSL around 17:00 to 17:30 CET. After stopping at the OSL airport, the bus will continue to central Oslo.
Organization
The 2026 Winter School is organized by a team of volunteers at the University
of Oslo, supported by a programme committee from the OpenEuroLLM, Circle U, and
NLPL networks and beyond, please see below.
For all inquiries regarding registration, the programme, logistics,
or such, please contact nlpl-training@ifi.uio.no.
The programme committee is comprised of (in alphabetical order):
- Jenia Jitsev (Forschungszentrum Jülich, Germany)
- Andrey Kutuzov (University of Oslo, Norway)
- Alessandro Lenci (University of Pisa, Italy)
- Stephan Oepen (University of Oslo, Norway)
- Sampo Pyysalo (University of Turku, Finland)
- David Salinas (ELLIS Institute, Germany)
- Gema Ramirez-Sanches (Prompsit Language Engineering, Spain)
- Jörg Tiedemann (University of Helsinki, Finland)
- Joaquin Vanschoren (Eindhoven University of Technology, The Netherlands)
- Guillaume Wisniewski (Paris Cité University, France)
Participants
- Adam Hrin, AMD Silo AI (Finland)
- Agnes Toftgård, The National Library (Sweden)
- Alicia Núñez Alcover, Prompsit (Spain)
- Anastasia Philipps, University of Oslo (Norway)
- Andrey Kutuzov, University of Oslo (Norway)
- Angelina Zanardi, National Library of Norway
- Anni Moisala, CSC – IT Center for Science (Finland)
- Artūrs Znotiņš, University of Latvia (Latvia)
- Barbara Heinisch, Eurac Research (Italy)
- Barbara Plank, Ludwig-Maximilians-Universität München (Germany)
- Charlotte Noel, LINAGORA Labs (France)
- Dalton Harmsen, Eindhoven University of Technology (Netherlands)
- David Salinas, ELLIS institute Tübingen (Germany)
- Diana Kylymnyk, University of Exeter (UK)
- Elizaveta Kuzmenko, Université Libre de Bruxelles (Belgium)
- Etienne Simon, University of Oslo (Norway)
- Faton Rekathati, The National Library (Sweden)
- Fedor Vitiugin, University of Turku (Finland)
- François Yvon, CNRS (France)
- Fred Philippy, University of Luxembourg (Luxembourg)
- Ghulam Muhammed Khan, University of Exeter (United Kingdom)
- Gianluca Barmina, University of Southern Denmark (Denmark)
- Hannah Clausen, University of Oslo (Norway)
- Hannan Mahadik, ELLIS Institute Tübingen (Germany)
- Iglika Nikolova-Stoupak, Sorbonne Université (France)
- Jan Hajič, Charles University (Czech Republic)
- Jiajing Wan, University of Bergen (Norway)
- Jindřich Helcl, University of Oslo (Norway)
- Johannes Gabriel Sindlinger, IT University of Copenhagen (Denmark)
- Jouni Luoma, AMD Silo AI (Finland)
- Julia Kreutzer, Cohere Labs (Canada)
- Justyna Sikora, The National Library (Sweden)
- Katarina Strani Herriot-Watt University (United Kingdom)
- Kevin Glocker, Linköping University (Sweden)
- Kristýna Onderková, Charles University (Czech Republic)
- Laurène Cave, Sorbonne Université (France)
- Lisa Yankovskaya, University of Tartu (Estonia)
- Maja Buljan, University of Oslo (Norway)
- Markus Heiervang, National Library of Norway
- Marthe Midtgaard, National Library of Norway
- Mattes Ruckdeschel, IT University of Copenhagen (Denmark)
- Maximilian Idahl, ellamind (Germany)
- Meihan Tong, University of Oslo (Norway)
- Muhammad Imran, University of A Coruña (Spain)
- Nam Luu, Charles University (Czech Republic)
- Neda Jamshidi, University of Sienna (Italy)
- Nikolay Arefev, University of Oslo (Norway)
- Nils Grünefeld, IT University of Copenhagen (Denmark)
- Pedro Ortiz Suarez, Common Crawl Foundation (USA)
- Rolv-Arild Braaten, National Library of Norway
- Romina Oji, Linköping University (Sweden)
- Sampo Pyysalo, University of Turku (Finland)
- Shanshan Xu, University of Copenhagen (Denmark)
- Shenbin Qian, University of Oslo (Norway)
- Stephan Oepen, University of Oslo (Norway)
- Taja Kuzman Pungeršek, Jožef Stefan Institute (Slovenia)
- Tita Enstad, National Library of Norway
- Tommaso Green, University of Mannheim (Germany)
- Tudor Nicolae Mateiu, Prompsit (Spain)
- Vladislav Mikhailov, University of Oslo (Norway)
- Wafa Aissa, UCLouvain (Belgium)
- Xiaorui Yu, King's College London (UK)
- Yihang Lu, Sorbonne Université (France)
- Yiheng Wu, University of Helsinki (Finland)
- Yves Scherrer, University of Oslo (Norway)
- Zihao Li, University of Helsinki (Finland)